Hazm library
Contribution
Before delving into my contributions, let me introduce the hazm library, a crucial tool for natural language processing in Persian. Hazm is an open-source Python library, tailored to streamline linguistic tasks in Persian, offering a wide range of linguistic functionalities.
My commitment to advancing Persian language processing extends beyond code contributions. As one of the main contributors to the hazm library, I played a pivotal role in shaping its capabilities. In addition to introducing key modules, I have enriched the library's resources by incorporating some extraordinary pretrained models. These models further empower the hazm community, providing advanced language processing capabilities right out of the box.
brief description about my contribution encompass:
Hazm 0.8
Implement WordEmbedding and SentEmbeding modules.
Add a pretrained fasttext Word Embedding model.
Add a pretrained Sentence Embedding model.
View more details on release notes of Hazm 0.8.
Hazm 0.9
Windows compaitiblity by using Python-crfsuite instead of Wapiti.
Added pretrained Chunker and POSTagger models with Python-crfsuite.
Implement train function of sent and word embeding.
Implement keywordExtraction with the embedRank approach as a sample of Hazm usage.
Improve the accuracy of POSTagger and Chunker.
View more details on release notes of Hazm 0.9.
Hazm 0.9.2
Add pretrained DependencyParser models.
Improve test coverage.
View more details on release notes of Hazm 0.9.2.

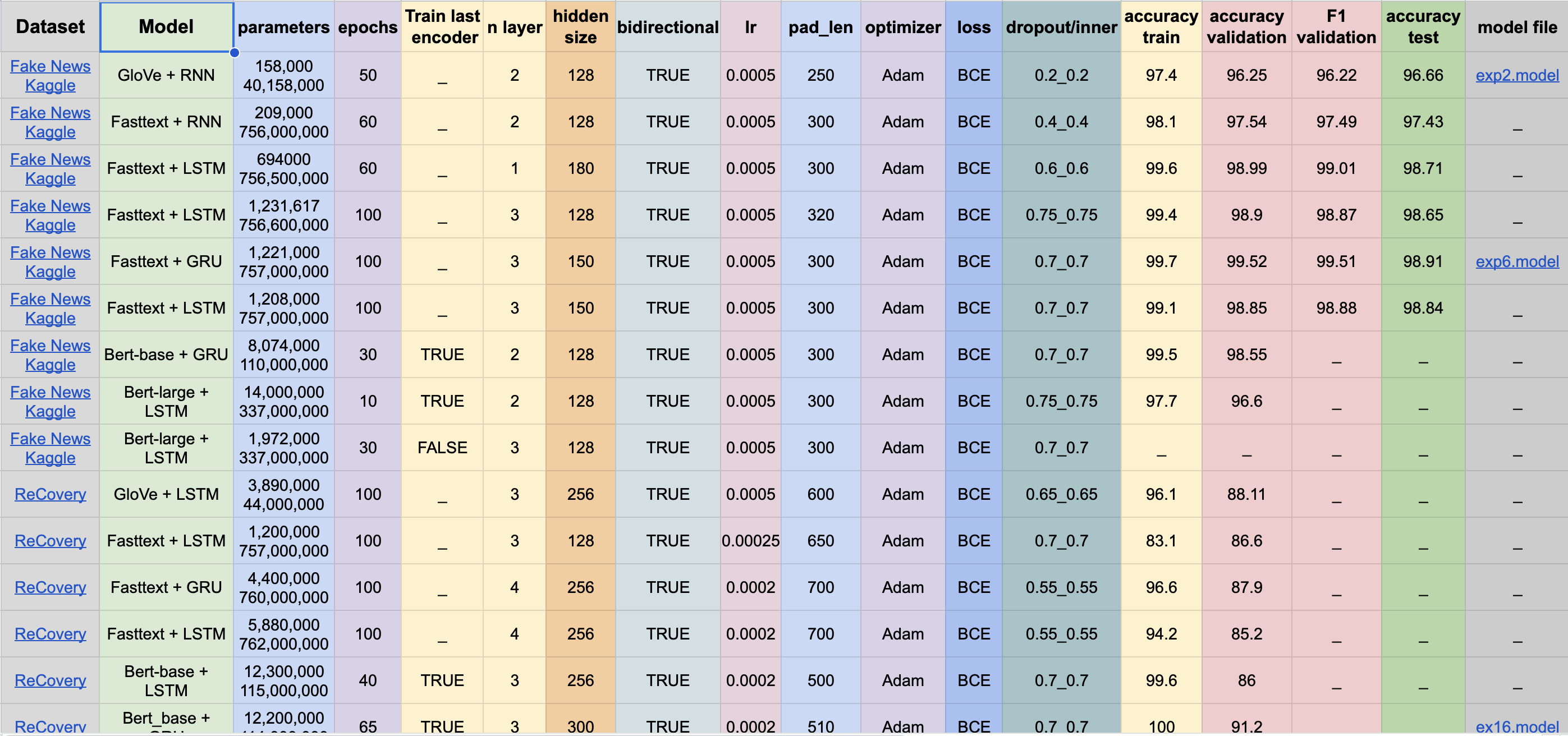
This project focuses on implementing and exploring various configurations for Rumour Detection using PyTorch. The repository not only includes the PyTorch implementation of the classification models but also features an intuitive interface for easily tuning, testing different training configurations, and adapting preprocessing steps.

This repository contains implementations of a Persian Part-of-Speech (POS) tagger using different approaches. The implemented models include PyTorch, TensorFlow, SpaCy, Average Perceptron, and Python-crfsuite.
Book
Recommendation System
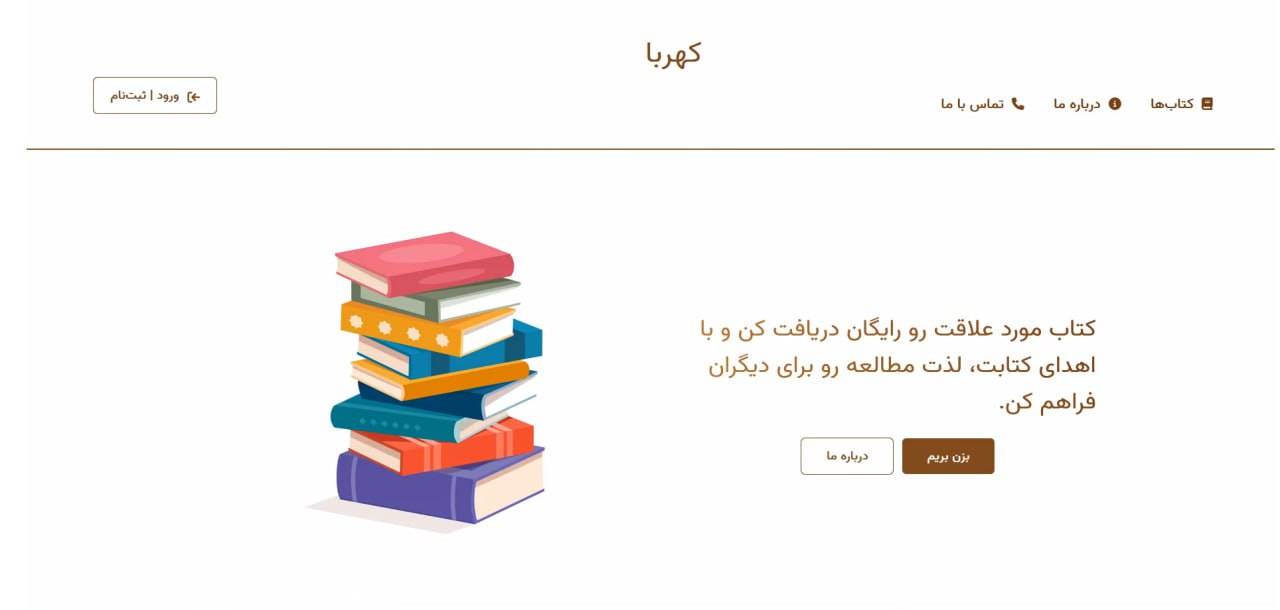
This repository contains the implementation of a Book Recommendation System for a book donation website. The system suggests the most relevant books to users based on the abstracts of the books. It utilizes embeddings, cosine similarity, and PCA (Principal Component Analysis) for recommendation.
Persian EmbedRank
Keyword Extraction
This repository contains the implementation of a Persian keyphrase extraction system using the EmbedRank method. The EmbedRank algorithm has been adapted and customized for the Persian language. The system includes trained models for Persian sentence embedding and part-of-speech (POS) tagging, utilizing the Hazm library.
Clothes
Recommendation System

This repository focuses on the implementation of a clothes recommendation system that tailors suggestions based on user preferences. We extract user's taste by asking some questions and then, represent it with a numeric vector. Finally, we utilize some similarity functions and clustering algorithms like Kmeans++ to recommend clothes. You can find out more details about this recommendation system on this google slide link that is representation of the system.
Persian AI-generated
text Detection
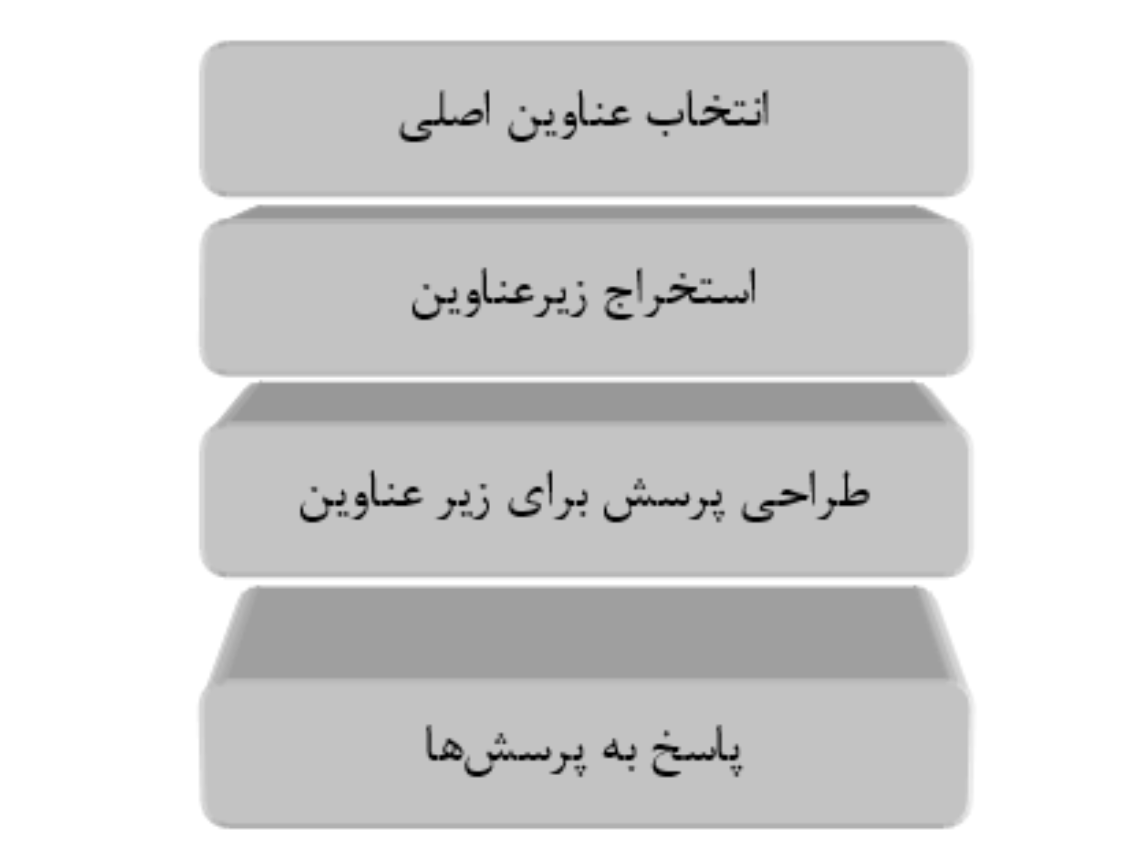
This project aims to extract Persian texts from the OpenAI GPT (Generative Pre-trained Transformer) library to create a valuable dataset for training models in the detection of AI-generated text. Please note that this project is currently under construction and is not yet completed.